דמיינו שאתם שולחים תמונה של חשבונית מבולגנת לאפליקציה בטלפון, והיא לא רק מזהה את הסכום – היא קוראת את כל הפרטים, מנתחת את הנתונים, ומציעה איך לחסוך כסף בפעם הבאה. זה לא מדע בדיוני; זה העתיד של מודלים מולטימודליים 2026. בשנים האחרונות, AI עבר מהבנת טקסט פשוטה ליכולת לעבד תמונות, וידאו ואפילו קול בו זמנית. Meta כבר שחררה את Llama 3.2 – מודלים פתוחים שרצים על מכשירים ניידים ומתחרים ב-GPT-4o. עד 2026, נראה AI שמבין את העולם כמו שאנחנו: רואה, קורא ומסיק מסקנות. מוכנים לצלול פנימה?
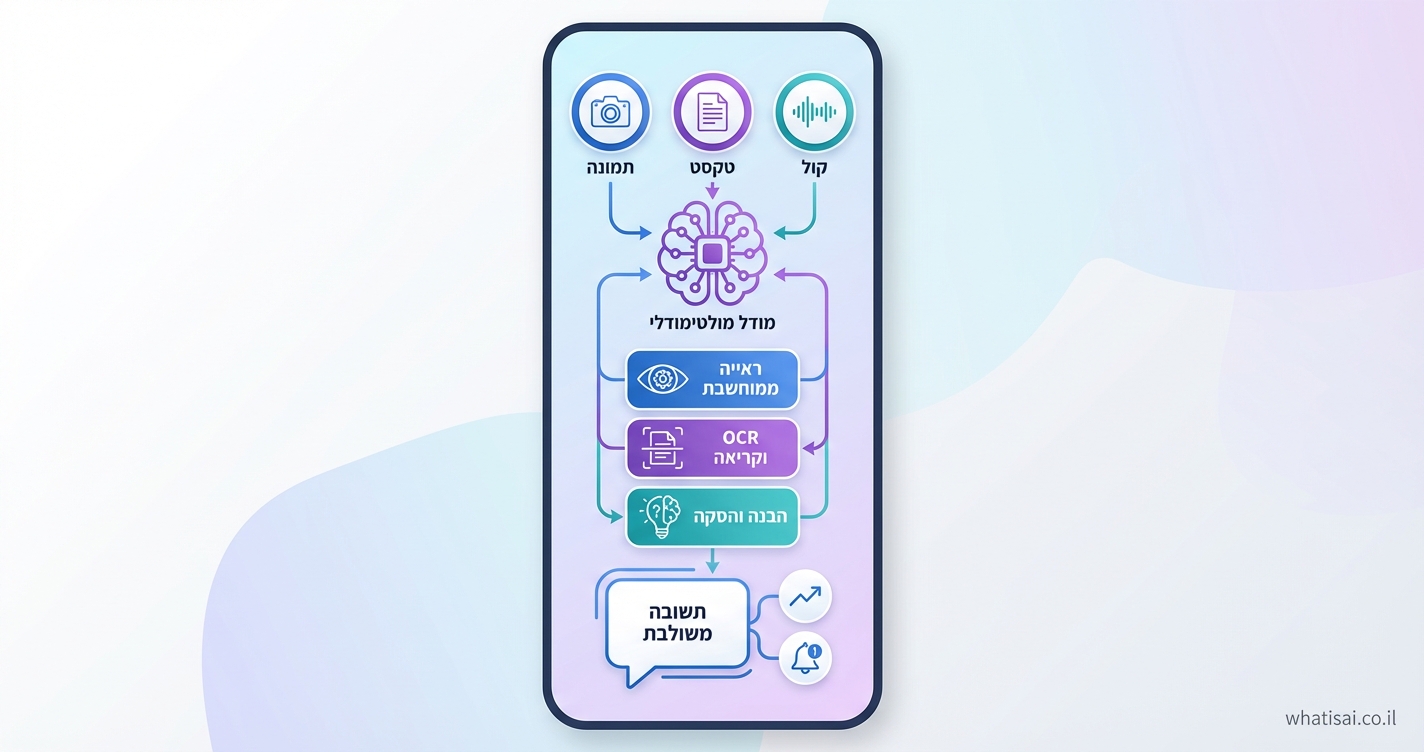
מהם מודלים מולטימודליים ואיך הם שונים ממודלים מסורתיים?
מודלים מולטימודליים הם כמו מוח אנושי מיניאטורי: הם לא מסתפקים בטקסט בלבד, אלא משלבים נתונים מ'חושים' שונים – תמונות, טקסט, וידאו וקול. בניגוד למודלים כמו GPT-3 שקראו רק מילים, מודלים מולטימודליים 2026 יעבדו הכל יחד להבנה עמוקה יותר. דוגמה? תארו לעצמכם רובוט שרואה חפץ, קורא את התווית ומחליט איפה לשים אותו – בלי צורך בהוראות נפרדות.
הבדלים מרכזיים
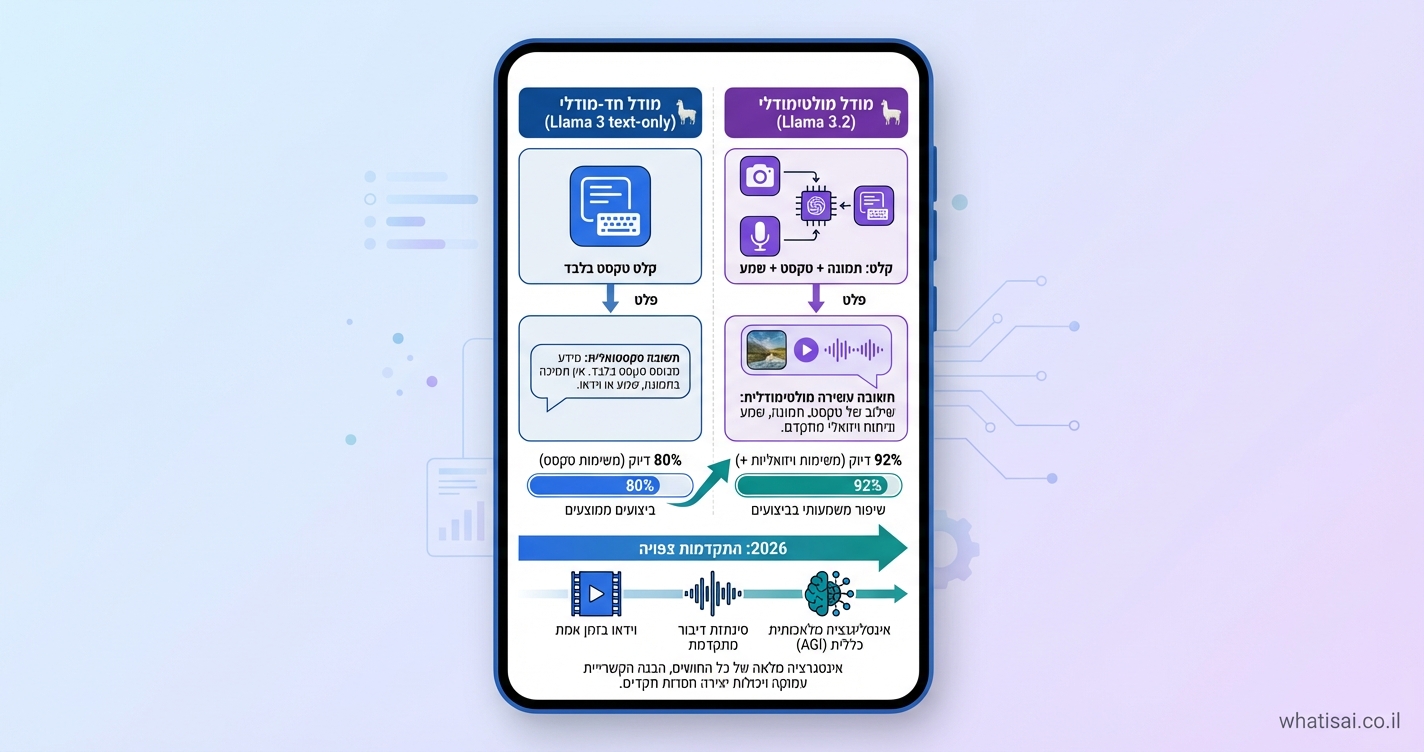
- מודלים חד-מודליים: מתמחים בתחום אחד, כמו עיבוד שפה טבעית (NLP).
- מולטימודליים: משלבים, כמו Llama 3.2 שמבין תמונות וטקסט ביעילות גבוהה.
לפי מאמרים מ-Hugging Face, Llama 3.2 11B ו-90B הם הראשונים הפתוחים שמציעים OCR, כתוביות וזיהוי חזותי, ומתקרבים לביצועים של מודלים סגורים. זה פותח דלת לקהילה להאיץ חידושים.
התקדמות פורצת דרך: Llama 3.2 ומתחריה
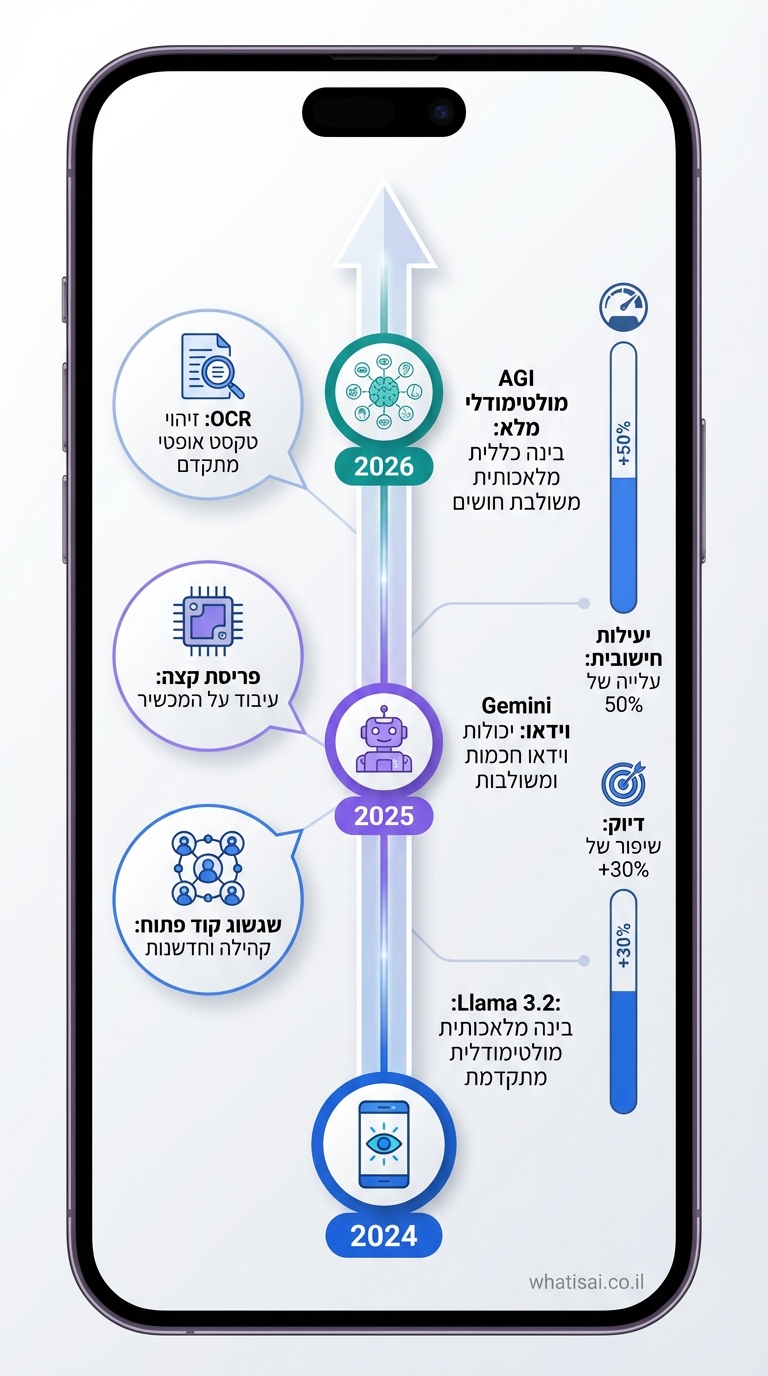
Meta שחררה את Llama 3.2 ב-2024 – מודלים קלים ל-edge devices, שרצים על טלפונים ללא ענן. הם מצטיינים במשימות תמונה-טקסט, עם ביצועים ברמה עולמית בפחות כוח חישוב. Andrej Karpathy צייץ שזה "קפיצה ענקית" ב-AI פתוח, שמתקרב למודלים סגורים כמו GPT-4V. VentureBeat מדווח: Llama 3.2 מאתגר את GPT-4o בהבנת גרפים ושאלות על מסמכים.
מודלים מובילים היום
- Llama 3.2 (Meta): פתוח, יעיל, זמין ב-Hugging Face.
- Gemini 1.5 (Google): משלב וידאו ואודיו.
- מודלים נוספים: Phi-3.5-Vision מ-Microsoft.
עד 2026, צפוי פתיחת מקור לשלוט, עם אפליקציות בכל מקום – מרפואה לשירות לקוחות, כפי ש-Forbes מציין.
יכולות הליבה: AI שרואה, קורא ומבין
מודלים מולטימודליים 2026 יראו כמו עיניים חכמות: זיהוי עצמים, ראייה ממוחשבת, וקריאת טקסט מ-IPhone תמונות (OCR). Llama 3.2 כבר עושה זאת – קורא חשבוניות, מנתח גרפים ומסביר ממים. ההבנה מגיעה משילוב: הרשת רואה תמונה, מפענחת טקסט בה ומייצרת תשובה לוגית.
דוגמה יומיומית: שולחים תמונה של מתכון מבולגן – AI מזהה מרכיבים, מתקן כמות ומציע שינויים תזונתיים. זה כמו שף-רובוט אישי.
יישומים בעולם האמיתי ומגמות עסקיות
בעסקים, מודלים כאלה משנים משחק: שירות לקוחות שרואה צילום תקלה ומפענח פתרון בזמן אמת. בבריאות – ניתוח תמונות רפואיות עם דוחות טקסט. Forbes חוזה: עד 2026, AI מולטימודלי יטפל בווידאו+אודיו, מוביל ל-AGI. דוגמה: אפליקציות Edge Computing על מכשירים, כמו Llama 3.2 בטלפון.
- רפואה: זיהוי מחלות מתמונות + היסטוריה טקסטואלית.
- חינוך: הסבר תמונות היסטוריות.
- רובוטיקה: NVIDIA AI פיזי שמבין סביבה.
כש-AI agents מעבדים אירועים ממקורות מרובים, כלים כמו WebhookAgent מספקים תשתית לתורים לאירועים בפיפליינים מולטימודליים.
אתגרים בדרך ל-2026 והפתרונות
לא הכל ורוד: מודלים זקוקים להרבה נתונים, ויש בעיות פרטיות ב-edge. Karpathy מציין צורך בשיפור וידאו/אודיו. פתרונות? אתיקה של AI ולמידת העברה. עד 2026, צפויה התקדמות כמו 17 תחזיות AI, עם מודלים יעילים יותר.
למידע נוסף, בקרו ב-AI לכולם.
למידע נוסף, בקרו ב-AI לקריאת מסמכים.
איך זה עובד בפועל? דוגמאות ידנית
קחו Llama 3.2 מ-Hugging Face: התקינו ב-Python עם PyTorch. העלו תמונה, שאלו "מה כתוב כאן?" – וקבלו OCR + ניתוח. צעדים:
- התקינו: pip install transformers.
- טענו מודל: LlavaNextForConditionalGeneration.
- קלט: תמונה + שאלה בעברית.
- פלט: הבנה מלאה.
בעסקים, שילבו עם RPA לאוטומציה. נסו בעצמכם – זה מהיר!
שאלות נפוצות
מה ההבדל בין מודלים מולטימודליים ל-LLM רגילים?
LLM כמו ChatGPT מתמקדים בטקסט, בעוד מולטימודליים משלבים תמונות/וידאו. Llama 3.2 מוסיף ראייה ללא צורך במודלים נפרדים, מהיר יותר ויעיל – אידיאלי ל-2026 עם אפליקציות ניידות.
האם מודלים מולטימודליים פתוחים בטוחים לשימוש?
כן, עם קוד פתוח כמו Llama 3.2, הקהילה בודקת באגים. השתמשו ב-XAI ל שקיפות. אתגרים כמו הטיות נפתרים בעדכונים, במיוחד בעברית עם fine-tuning.
מתי נראה מודלים מולטימודליים 2026 בעברית מלאה?
כבר עכשיו Llama תומך עברית טוב, ועד 2026 – כיסוי מלא בווידאו/אודיו. כלים כמו סופרבוט צ'אט GPT בעברית מובילים.
איך להתחיל עם Llama 3.2?
הורידו מ-Hugging Face, הריצו מקומית. דרוש GPU חלש בלבד. מדריכים זמינים, וקהילה תומכת fine-tuning ליישומים אישיים.
מה הצפי ל-2026?
AI שמבין סביבה מלאה, רובוטים חכמים ויישומים AGI. פתוח ידגום, עם יעילות x10.
סיכום: העתיד כבר כאן – התחילו היום
מודלים מולטימודליים 2026 יגרמו ל-AI להיות חלק מחיי היומיום, מרואה תמונות ועד הבנת עולם. אל תחכו – נסו Llama 3.2, למדו עוד על תחזיות, והצטרפו למהפכה. מה תבנו ראשון? שתפו בתגובות!